正则表达式 - 必知必会
正则表达式 ( Regular Expression )是强大、便捷、高效的文本处理工具。
正则表达式本身,加上如同一门袖珍编程语言的通用模式表示法(general pattern notation),赋予使用者描述和分析文本的能力。
配合上特定工具提供的额外支持,正则表达式能够添加、删除、分离、叠加、插入和修整各种类型的文本和数据。
——《精通正则表达式》
测试工具
本地测试工具 (RegexBuddy)
下载地址 : https://www.regexbuddy.com/
软件截图 :
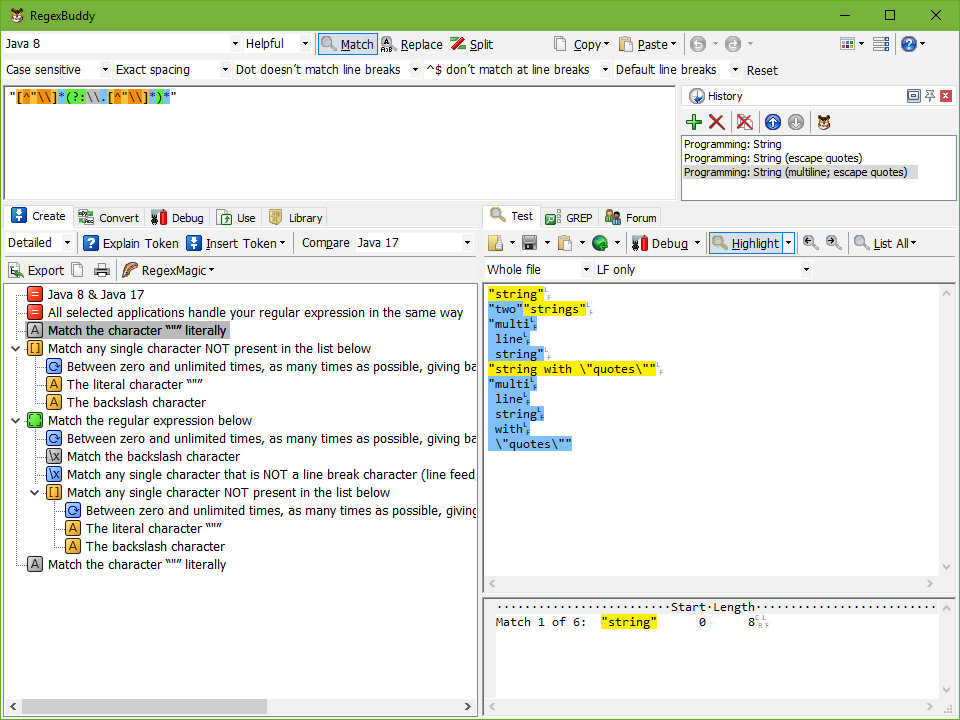
常用功能说明:
- 左上角可以设置 实际应用正则的编程语言,这里代表着不同流派的正则
- 往右挨着的功能是 匹配 和 替换 ,要配合着下面的 Test 去使用
Case sensitive一般选择 不匹配大小写,会避免一些麻烦- 下方
Test中要注意那一行最右侧的 下拉选项,里面包含 ”Whole file“ 、”Page by page“ 和 ”Line by line“ ,需要根据实际情况选择 Debug可以用 也可以去 regex101网站调试 (翻墙访问会快一些)- 打开
Hightlight和List All下的Update Automatically会很方便
在线测试工具
在线学习网站
快速入门
完整的正则表达式由
两种字符构成。特殊字符 称为 元字符 (metacharacters)
普通文本字符 称为 文字 (literal)
术语汇总
- 正则(regex):“正则表达式”的简称
- 匹配(matching):这个正则表达式能在字符串中找到匹配的文本。
- 元字符(metacharacter):一个字符是否为元字符,取决于应用的具体情况。流派不同,字符转义的规定也不相同。
- 流派(flavor):由Perl语言的正则表达式开创的流派,功能强大,其他语言汲取其中灵感发展成不同流派。
- 子表达式(subexpression):指整个正则中的一部分,通常是括号内的表达式,或由
|分隔的多选分支。例如:H[1-6]\s*的子表达式为H、[1-6]和\s*- 字符(character):一个字节所代表的单词取决于计算机如何解释。单个字节的值不会变化,但这个 值 所代表的 字符 却是由解释所用的编码来决定的。要确保 编码 的问题,自己的视角要和工具的视角相同。
字符组
匹配若干字符之一。
[……]它容许使用者列出在某处期望匹配的字符,通常被称作 字符组 。
普通字符组
<H[123456]> 可以匹配 <H1> <H2> <H3> <H4> <H5> <H6> 。[123456] 表示的意思是匹配1到6任意一个数字,是 或 的含义。
字符组元字符
<H[123456]> 可以简写成 <H[1-6]> 。中括号中的 - 就是字符组元字符。
只有当 - 出自现在[]内开头时候,才表示普通的 - 字符,例如 <H[-1-6]>,匹配的是 <H1> <H2> <H3> <H4> <H5> <H6> <H-> 。
注意:这种简写遵循ASCII码表的顺序。
例如 十六进制可以用[0-9a-fA-F] 正则匹配。[0-Z] 则可以匹配 2、C、=、? 但是不可以匹配 a、k、_、{ 。
排除型元字符
[^……] 字符组开头的 ^ (脱字符)表示 排除 (negate) 的意思。
例如 <H[^1-6]> 不希望匹配 <H1> <H2> <H3> <H4> <H5> <H6> 这几个,但可以匹配 <H8> <HA> <H!> 等等。
元字符 .
元字符 .(通常称为点号 dot 或者 小点point)是用来匹配任意字符的字符组的简便写法。它不匹配换行符,除非开启了”单行模式“。
字符组简记法
| 字符组 | 简记 |
|---|---|
| \d | 数字。0 到 9,等价 [0-9] |
| \D | 非数字字符。等价 [^0-9] |
| \w | 单词中的字符。一般等价[0-9A-Za-z_] 但某些工具不匹配下划线 |
| \W | 非单词中的字符。等价[^0-9A-Za-z_] |
| \s | 空白字符。通常等价[ \f\n\r\t\v] |
| \S | 非空白字符。等价[^\s] |
量词
量词表示不确定的长度,其通用形式为 {m,n} ,其中 m 和 n 是两个非负整数,且 m ≤ n 。表达式中不能有空格。
量词的一般形式及说明
| 量词 | 说明 |
|---|---|
| {n} | 匹配的字符必须出现n次 |
| {m,n} | 匹配的字符最少出现m次,最多出现n次 |
| {m,} | 匹配的字符出现m次及以上 |
| {0,n} | 匹配的字符可以不出现,也可以出现,最多n次。(某些编程语言支持写成{,n},但不推荐) |
常用量词
?、+ 和 * ,可以理解为“量词的简记法”
| 量词 | 等价 |
|---|---|
| * | {0,} |
| + | {1,} |
| ? | {0,1} |
举例
匹配
<h1 id='title'>我是标题</h1> <input type="submit" value="提交" />中的 html标签
| 标签 | 正则 |
|---|---|
| 开始标签 | <[^/][^>]+> |
| 结束标签 | </[^>]+> |
| 自闭合标签 | <[^/>]+/> |
你会发现开始标签正则也可以匹配自闭合标签。需要改成<[^/][^>]*[^/]> 。但这个正则出现2次[^/]是占用2个字符,无法匹配 <B> 这种标签。需要用到 环视 的写法,暂不做讨论。
匹配优先量词
回到刚才的举例,如果正则为 <.*> 得到的结果为 第一个< 到最后一个 > 中的全部内容。
匹配优先(贪婪) :首先需要记住,标准匹配量词(?、*、+ 以及 {min,max})都是“匹配优先(greedy)”的,它们总是尝试匹配尽可能多的字符直到匹配上限为止。
例如:用正则 \d*\d+ 去匹配 0123456789 。\d* 能匹配到 012345678 ,而\d+只能匹配到9
忽略优先量词
还是那个举例,如果只想要匹配最开始的标签如何去写这个正则呢?
需要用到 忽略优先量词(懒惰) ,如果不确定是否要匹配,忽略优先会选择“不匹配”的状态,在尝试表达式中之后的元素,如果尝试失败,再回溯,选择之前保存的“匹配”的状态
只想要匹配最开始的标签的答案为 <.*?>
再来个例子:用正则 \d*?\d+? 去匹配 0123456789 。\d*? 能匹配到最少次数是0次,结果是空 ,而\d+?能匹配到最少的1次,但它们都会逐个去匹配0-9这一排数字10次。
括号
分组
分组:将相关元素归拢到一起,构成一个整体。
捕获型括号的编号是按照开始括号出现的次序,从左至右计算的。
例如:
- 匹配
<h1>我是标题</h1>的正则为<h1>(.*?)</h1>。匹配的文本 和 替换中存储的$1为:我是标题。 - 匹配 IPv4 地址(127.0.0.1)的正则为
(\d{1,3}\.){3}\d{1,3}。匹配的文本 和 替换中存储的$0为:127.0.0.1,$1 为0.。要理解这个表达式,请按下列顺序分析它:\d{1,3}匹配1到3位的数字,(\d{1,3}.){3}匹配三位数字加上一个英文句号(这个整体也就是这个分组)重复3次,最后再加上一个一到三位的数字(\d{1,3})。
非捕获分组
仅用于分组的括号
(?:……),不能用来提取文本,而只能用来规定多选结构或者量词的作用对象。它们不会按照
$1 、$2去编号。如果没用用到引用分组,尽量使用非捕获型的括号,性能会好。
例如:匹配 IPv4 地址(127.0.0.1)的正则为 (?:\d{1,3}\.){3}\d{1,3} 。匹配的文本 和 替换中存储的$0为:127.0.0.1 。
引用分组
引用分组:将子表达式匹配的文本存储起来,供之后引用。
可以用“\1”,“\2”,“\3” 来反向引用
例如:匹配下面文本的正则,可以写成 <(.*?)>.*?</\1>
<h1>h1</h1>
<h2>h2</h2>
<h3>h3</h3>匹配叠字可以写成([\u4e00-\u9fa5])\1
圈圈圆圆圈圈
天天年年天天
的我深深看你的脸
生气的温柔
埋怨的温柔 的脸 多选结构
多选结构的形式是
(……|……),在括号内以竖线分隔开多个子表达式。在一个多选结构内,多选分支的数目没有限制。在匹配时,整个多选结构视为一个整体,只要其中某个子表达式能匹配就能成功。如果所有表达式都不能匹配,则匹配失败。
多个子表达式都能匹配的时候,匹配的结果为最左边的匹配结果。(精确的放左边)
刚才匹配Ipv4地址的例子不太规范,可以匹配到错误数据。优化的正则为
(?:(?:2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(?:2[0-4]\d|25[0-5]|[01]?\d\d?)
匹配名为xxx的各种文件名后缀的正则: xxx\.(?:avi|mp\d|jpg|xls|ppt|txt)
命名分组
并不是通行的功能,暂不讨论
断言
单词边界
\b 匹配一个单词边界,即字与空格间的位置。
行起始/结束位置
单词边界匹配的是某个位置而不是文本,在正则中,这里匹配位置的元素叫 锚点(anchor)。
^、$分别匹配字符串的 开始位置 和 结束位置 。
在按下回车键就输入了一个行终止符(Line terminal)。不同平台下的终止符不相同。
| 平台 | 行终止符 |
|---|---|
| UNIX/Linux | \n |
| Windows | \r\n |
| Mac OS | \n (OS 9 之前的版本 为 \r) |
环视
环视(look-around)用来“停在原地,四处张望”,类似单词边界,在它旁边的文本需要满足某种条件,而且本身不匹配任何字符。
回到量词开始标签的举例,再来改进下。增加一个要匹配的文本 <p title=">" class='p_style' >标签不规范</p> ,<[^/][^>]*[^/]> 无法满足这样的匹配,返回 <p title="> 的结果。
修改成 <(?!/)(?:'[^']*'|"[^"]*"|[^'">])+(?<!/)> 则可以满足,也可以满足 <B> 这种标签的匹配。
这个表达式出现了两种环视 (?!……) 、(?<!……) ,它们的名字是“否定顺序环视”,“否定逆序环视”。“否定”的意思是“ **如果正则表达式匹配成功,则当前位置匹配失败 **”,而“顺序”和“逆序”则表示正则需要匹配的文本所在的位置。
环视分类
环视一共分为4种。肯定顺序环视(positive-lookahead)、否定顺序环视(negative-lookahead)、肯定逆序环视(positive-lookbehind) 和 否定逆序环视(negative-lookbehind)
| 名称 | 记法 | 判断方向 | 结构内表达式匹配成功的返回值 |
|---|---|---|---|
| 肯定顺序环视(零宽度正预测先行断言) | (?=……) | 向右 | True |
| 否定顺序环视(零宽度负预测先行断言) | (?!……) | 向右 | False |
| 肯定逆序环视(零宽度正回顾后发断言) | (?<=……) | 向左 | True |
| 否定逆序环视(零宽度负回顾后发断言) | (?<!……) | 向左 | False |
当前位置是朝右判断,则是顺序环视,朝左判断是逆序环视;要求子表达式能匹配的字符串出现,则为肯定环视,不能出现则为否定环视。
举例
去掉下面文本的空格,英文单词间的除外
中 英文混 排, some English word, 有 多余 的空白字 符
分析:
匹配空白符 \s,some_English_word (下划线的位置代替空白符)从左边看不能出现英文字母([a-zA-Z]),从右边看也不能出现英文字母。
所以左右要添加否定逆序环视和否定顺序环视,故而得到 (?<![a-zA-Z])\s+(?![a-zA-Z]) ,替换的文本(Replacement text)设置为空,在进行替换操作。
P.S. 能不能改写成肯定环视?左侧肯定不包含字母,右侧肯定不包含字母,(?<=[^a-zA-Z])\s+(?=[^a-zA-Z])
这个问题涉及到 肯定环视 和 否定环视 的一大根本不同是,肯定环视 要判断成功,字符串中必须有字符由换式结构中的表达式匹配;而 否定环视 要判断成功,却有两种情况:1.字符串中出现了字符,但这些字符不能由环视结构中的表达式匹配。 2.字符串中不再有任何字符。也就是这个位置的字符串的起始位置或者结束位置。区别如下。
| 正则 | 结果说明 |
|---|---|
(?<![a-zA-Z])\s+(?![a-zA-Z]) |
否定环视,去掉了首尾空白 |
(?<=[^a-zA-Z])\s+(?=[^a-zA-Z]) |
肯定环视,无法去掉字符串中的首尾空白,这是因为 \s+ 虽然可以匹配空白符,但其左侧没有任何字符,所以 (?<=[^a-zA-Z]) 无法匹配成功,末尾也是一样的道理。 |
电子邮件中,更准确的主机名验证。
E-mail地址以@分隔两段,前面的是用户名(username),之后的是主机名(hostname)。用户名一般允许英文大小写、数字、点号等比较简单。
但根据规范,主机名以点号分割多个域名字段(label), 每个域名字段可以包含英文大小写、数字、短横,但横线不能出现在最开头位置(e.g. mail.xxx.com)。
每个域名字段长度最多为63个字符,整个主机名的长度最多255个字符。
这个表达式
([-a-zA-Z0-9]{1,63}\.)*[-a-z-A-Z0-9]{1,63},有两个问题:1.它允许第一个字符是横线-;2.它没有限定整个主机的长度最长为255个字符。
分析:
它允许第一个字符是横线
-。可以改写成[a-zA-Z0-9][-a-zA-Z0-9]{0,62}\.但这样的环视更好(?!-)[-a-zA-Z0-9]{1,63}\.它没有限定整个主机的长度最长为255个字符。
为了保证整个主机名字符串长度小于255个字符,主机名全部可能出现的字符都用
[-a-zA-Z0-9.]表示,所以对应的肯定顺序环视就是(?=[-a-zA-Z0-9.]{0,255})。如果单独给出一个字符串去判断,需要在这个环视末尾增加$;如果在一长段文本中提取,那么主机名后面还会有其它字符,只是这些字符不能是[-a-zA-Z0-9.](可能是空白符,可能是末尾),使用否定顺序环视(?![-a-zA-Z0-9.])可以兼顾这种情况。最终得到的正则为:
(?=[-a-zA-Z0-9.]{0,255}(?![-a-zA-Z0-9.]))(?:(?!-)[-a-zA-Z0-9]{1,63}\.)*(?:(?!-)[-a-zA-Z0-9]){1,63}完整在文本中匹配类似
abc@mail.xxx.comEmail地址的 正则为:[\w\-.]+@(?=[-a-zA-Z0-9.]{0,255}(?![-a-zA-Z0-9.]))(?:(?!-)[-a-zA-Z0-9]{1,63}\.)*(?:(?!-)[-a-zA-Z0-9]){1,63}P.S.
这是我测试的Email地址 mine@mail.xn--z4q5h38stwcs83anlqrw4b.xn--6qq986b3xl 试着提取它
转义
字符组转义
字符组内 ] 需要转义成 \] ; [-09]等价 [0\-9] ; [ab^]等价 [\^ab]
元字符转义
| 元字符 | 转义 |
|---|---|
| [ | \[ |
| { | \{ |
| () | \( ,\) |
| * , + , ? | \* , \+ , \? |
| . | \. |
| | | \ |
| ^ , $ | \^ , \$ |
| $num | \$ 或 $$ 在替换的 replacement 中转义 |
常用语言正则特性
这里只记录了
Python、Java和JavaScript的常用特性
| 特性 | JS | Java | Python |
|---|---|---|---|
\d \w \s 字符组简记 |
ASCII匹配规则 | ASCII匹配规则 | ASCII匹配规则 |
\1 \9 引用分组 |
√ | √ | √ |
| 替换中的引用分组 | $num | $num | \g<num> |
| 命名分组 | × | × | 用(?P<name>regex)表示命名分组用 (P=name)在表达式中引用分组用 \g<name>在替换中引用 |
^ |
√ | √ | √ |
$ |
$无法匹配文本末尾结束符之前的位置 |
√ | √ |
(?=regex)(?!regex) |
√ | √ | √ |
(?<=regex) (?<!regex) |
× | 逆序环视中的正则能匹配到的文本长度必须有上限 | 逆序环视中的正则能匹配到的文本长度必须是固定的 |
| 不区分大小写模式 | √ | √ | √ |
| 单行模式 | × | √ | √ |
| 多行模式 | √ | √ | √ |
| 注释模式 | × | √ | √ |
| Unicode Property | × | √ | × |
| Unicode Block | × | √ | × |
| Unicode Script | × | × | × |
实战技巧
设置常用的快捷输入
找到系统的输入法中的,用户自定义短语功能。设置一个快捷键,输入如下正则,会方便很多
| 正则 | 说明 |
|---|---|
([\D\d]*?) |
捕获全部字符,用于提取HTML标签外部的内容 |
([^>]*?) |
捕获href中的网址,用于提取HTML标签内部的内容 |
(.*?) |
单行匹配 |
[\D\d]*? |
对应上面,只是去掉了捕获 |
[^>]*? |
同上 |
.*? |
同上 |
(\d{4}-\d{1,2}-\d{1,2}\s+\d{1,2}:\d{1,2}:\d{1,2}) |
捕获时间的正则,具体情况在此基础上修改 |