ddddocr使用与模型训练
基本使用方法
ddddocr(带带弟弟OCR):是一个很好用的ocr识别库
ddddocrGitHub:https://github.com/sml2h3/ddddocrdddd_trainer 是 ddddocr 的训练工具
dddd_trainerGitHub:https://github.com/sml2h3/dddd_trainer
测试样例

实现代码
import ddddocr
if __name__ == '__main__':
test_pic_path = r'test_pic.png'
ocr = ddddocr.DdddOcr()
with open(test_pic_path, 'rb') as f:
image_bytes = f.read()
result = ocr.classification(image_bytes)
print(result)识别结果
欢迎使用ddddocr,本项目专注带动行业内卷,个人博客:wenanzhe.com
训练数据支持来源于:http://146.56.204.113:19199/preview
爬虫框架feapder可快速一键接入,快速开启爬虫之旅:https://github.com/Boris-code/feapder
谷歌reCaptcha验证码 / hCaptcha验证码 / funCaptcha验证码商业级识别接口:https://yescaptcha.com/i/NSwk7i
798=9
进程已结束,退出代码为 0识别的结果(798=9)实际结果还是有些差异,那么就需要自己训练一下模型。
训练方法
步骤1 标注训练数据
数据集支持两种格式:
- 从文件名导入
- 从文件中导入
从文件名导入格式
/root/images_set/
|---- abcde_随机hash值.jpg
|---- sdae_随机hash值.jpg
|---- 酱闷肘子_随机hash值.jpg从文件中导入格式
/root/images_set/
|---- labels.txt
|---- images
|---- 随机hash值.jpg
|---- 随机hash值.jpg
|---- 酱闷肘子_随机hash值.jpg
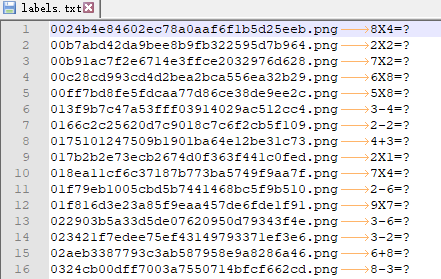
labels.txt文件内容为(其中\t制表符为每行文件名与label的分隔符)
随机hash值.jpg\tabcd
随机hash值.jpg\tsdae
酱闷肘子_随机hash值.jpg\t酱闷肘子本文中,由于是计算题,其中有?,但文件名中不能包含?,故使用第二种导入方法
训练的数据集,如下
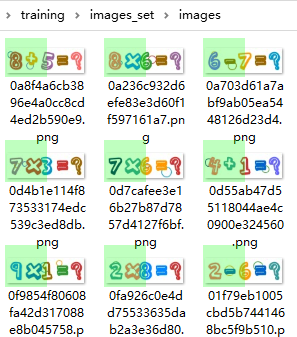
步骤2 创建训练项目
- 克隆项目
git clone https://github.com/sml2h3/dddd_trainer.git - 安装依赖
pip install -r requirements.txt -i https://pypi.douban.com/simple - 创建项目
python app.py create {project_name}
步骤3 缓存数据及训练
缓存数据
python app.py cache {project_name} /root/images_set/
如果是从labels.txt里面读取数据
python app.py cache {project_name} /root/images_set/ file
开始训练
python app.py train {project_name}
训练好的模型在
{project_name}\models下
如果 ‘export_onnx’ 报错 可以看看这个Issues 👉 https://github.com/sml2h3/dddd_trainer/issues/12
# 我是直接修改源码删掉这个参数
# def export_onnx(self, net, dummy_input, graph_path, input_names, output_names, dynamic_ax):
# torch.onnx.export(net, dummy_input, graph_path, export_params=True, verbose=False,
# input_names=input_names, output_names=output_names, dynamic_axes=dynamic_ax,
# opset_version=12, do_constant_folding=True, _retain_param_name=False)
def export_onnx(self, net, dummy_input, graph_path, input_names, output_names, dynamic_ax):
torch.onnx.export(net, dummy_input, graph_path, export_params=True, verbose=False,
input_names=input_names, output_names=output_names, dynamic_axes=dynamic_ax,
opset_version=12, do_constant_folding=True)测试
拷贝训练好的模型(onnx文件和charsets.json)
import ddddocr
if __name__ == '__main__':
test_pic_path = r'test_pic.png'
# 加载自己训练的模型
ocr = ddddocr.DdddOcr(charsets_path=r'charsets.json',
import_onnx_path=r'test_project_1.0_33_1000_2022-09-17-22-01-09.onnx')
with open(test_pic_path, 'rb') as f:
image_bytes = f.read()
result = ocr.classification(image_bytes)
print(result)训练结果如下
7-8=?ddddocr使用与模型训练
https://元气码农少女酱.我爱你/b61b33d893ac/